Ας υποθέσουμε ότι θέλουμε να ορίσουμε το τι σημαίνει σωστά δομημένη
αριθμητική έκφραση. Για να κάνουμε τα πράγματα πιο απλά (χωρίς να
χαθεί η ουσία) ας περιοριστούμε σε αριθμητικές εκφράσεις όπου
οι μόνες πράξεις είναι η πρόσθεση (+) και ο πολλαπλασιασμός (*),
και όπου ισχύουν οι συνηθισμένοι κανόνες για τις παρενθέσεις.
Ας υποθέσουμε επίσης ότι οι βασικές ποσότητες που φτιάχνουν μια έκφραση
συμβολίζονται όλες με το γράμμα ![]() .
Για παράδειγμα η έκφραση
.
Για παράδειγμα η έκφραση ![]() είναι μια σωστή έκφραση
ενώ η
είναι μια σωστή έκφραση
ενώ η ![]() δεν είναι.
δεν είναι.
Έχουμε δηλαδή ένα πολύ περιορισμένο αλφάβητο
Ένας γρήγορος και καθαρός τρόπος να τις ορίσουμε είναι να σκεφτούμε το πώς τις φτιάχνουμε: κολλάμε μαζί, με συγκεκριμένους κανόνες, μικρότερες εκφράσεις και φτιάχνουμε μεγαλύτερες. Δίνουμε έτσι τον εξής ορισμό.
Ορισμοί σαν τον παραπάνω (αλλά και αρκετά πιο περίπλοκοι) κωδικοποιούνται στις λεγόμενες context free γραμματικές. Πριν δώσουμε τον ακριβή ορισμό για αυτές ας πούμε ότι η context free γραμματική που αντιστοιχεί στον παραπάνω ορσιμό είναι η:
Με το σύμβολο
Με την παρακάτω ακολουθία μετασχηματισμών προκύπτει π.χ. η λέξη ![]()
| (κανόνας παραγωγής 3) | |||
| (κανόνας παραγωγής 4) | |||
| (κανόνας παραγωγής 2) | |||
| (κανόνας παραγωγής 3) | |||
| (κανόνας παραγωγής 1, τέσσερεις φορές) |
Εύκολα βλέπει κανείς ότι με όποιο τρόπο και να χρησιμοποιήσουμε
τους κανόνες παραγωγής δε μπορούμε να πάρουμε από την ![]() τη λέξη
τη λέξη ![]() .
.
Αν ![]() είναι μια context free γραμματική (CFG) και
είναι μια context free γραμματική (CFG) και
![]() ,
, ![]() είναι δύο λέξεις από τερματικά ή μη τερματικά σύμβολα,
τότε γράφουμε
είναι δύο λέξεις από τερματικά ή μη τερματικά σύμβολα,
τότε γράφουμε
Για παράδειγμα, αν ![]() είναι η γραμματική που ορίσαμε παραπάνω τότε
ισχύει
είναι η γραμματική που ορίσαμε παραπάνω τότε
ισχύει
Ορίζουμε επίσης
Έχοντας στα χέρια μας τον συμβολισμό αυτό μπορούμε εύκολα να ορίσουμε πλέον ποια είναι η γλώσσα που αντιστοιχεί σε μια λέξη (από τερματικά ή μη σύμβολα).
Τέλος ορίζουμε την γλώσσα της ![]() .
.
Θα χρησιμοποιούμε συνήθως τη συντομογραφία
Ας δούμε τώρα ένα παράδειγμα μιας CFG με παραπάνω από ένα
μη τερματικό σύμβολο.
Η γραμματική αυτή θα έχει ως γλώσσα της όλες τις λέξεις του
![]() που έχουν ίδιο πλήθος από
που έχουν ίδιο πλήθος από ![]() και
και ![]() . Θυμίζουμε
εδώ ότι αυτή η γλώσσα δεν είναι κανονική (αποδεικνύεται εύκολα
αυτό με χρήση του Λήμματος Άντλησης (Θεώρημα 5).
. Θυμίζουμε
εδώ ότι αυτή η γλώσσα δεν είναι κανονική (αποδεικνύεται εύκολα
αυτό με χρήση του Λήμματος Άντλησης (Θεώρημα 5).
Η γραμματική ![]() είναι η ακόλουθη:
είναι η ακόλουθη:
Απόδειξη: Κατ' αρχήν τα μόνα τερματικά σύμβολα που εμφανίζονται στους κανόνες της
Ας συμβολίζουμε για μια λέξη ![]() του
του
![]() με
με ![]() και
και ![]() αντίστοιχα το πλήθος των
αντίστοιχα το πλήθος των ![]() και
και ![]() που περιέχει.
που περιέχει.
Πρέπει να δείξουμε ότι ισχύει
![]() αν και μόνο αν
αν και μόνο αν
![]() .
Αλλά αν προσπαθήσουμε να δείξουμε μόνο αυτό θα συναντήσουμε
δυσκολίες. Παρ' ότι δείχνει αντιφατικό μας διευκολύνει
το να δείξουμε παράλληλα και άλλες δύο προτάσεις.
Έτσι θα δείξουμε με επαγωγή ως προς το μήκος της λέξης
.
Αλλά αν προσπαθήσουμε να δείξουμε μόνο αυτό θα συναντήσουμε
δυσκολίες. Παρ' ότι δείχνει αντιφατικό μας διευκολύνει
το να δείξουμε παράλληλα και άλλες δύο προτάσεις.
Έτσι θα δείξουμε με επαγωγή ως προς το μήκος της λέξης ![]() τις εξής τρείς ισοδυναμίες.
τις εξής τρείς ισοδυναμίες.
Όπως είπαμε
συμβολίζουμε με ![]() το μήκος της λέξης
το μήκος της λέξης ![]() και κάνουμε επαγωγή
ως προς
και κάνουμε επαγωγή
ως προς ![]() .
Αν
.
Αν ![]() , τότε
, τότε
![]() και
και ![]() παράγεται από
το
παράγεται από
το ![]() με τον τελευταίο κανόνα παραγωγής του
με τον τελευταίο κανόνα παραγωγής του ![]() ενώ δεν παράγεται από τα
ενώ δεν παράγεται από τα ![]() ή
ή ![]() , αφού όλοι οι κανόνες παραγωγής
των
, αφού όλοι οι κανόνες παραγωγής
των ![]() και
και ![]() παράγουν μη κενές λέξεις.
Βλέπουμε έτσι ότι ισχύουν και οι τρεις ισοδυναμίες για τη λέξη
παράγουν μη κενές λέξεις.
Βλέπουμε έτσι ότι ισχύουν και οι τρεις ισοδυναμίες για τη λέξη
![]() ,
τη μοναδική λέξη με μήκος
,
τη μοναδική λέξη με μήκος ![]() .
.
Υποθέτουμε τώρα επαγωγικά
ότι ισχύουν και οι τρεις άνω ισοδυναμίες για κάθε λέξη
![]() με
με
![]() .
.
Έστω τώρα ![]() μια λέξη με μήκος
μια λέξη με μήκος ![]() .
Αποδεικνύουμε την πρώτη ισοδυναμία:
.
Αποδεικνύουμε την πρώτη ισοδυναμία:
![]() .
.
![]()
Αφού
![]() υπάρχει μια ακολουθία παραγωγών της
υπάρχει μια ακολουθία παραγωγών της ![]() που αρχίζει από το
που αρχίζει από το ![]() και καταλήγει στη
και καταλήγει στη ![]() .
Αν το πρώτο γράμμα της
.
Αν το πρώτο γράμμα της ![]() είναι
είναι ![]() τότε στην πρώτη
παραγωγή αναγκαστικά χρησιμοποιείται ο κανόνας
τότε στην πρώτη
παραγωγή αναγκαστικά χρησιμοποιείται ο κανόνας
![]() .
Αυτό συνεπάγεται ότι
.
Αυτό συνεπάγεται ότι ![]() όπου
όπου ![]() είναι μια λέξη για την οποία
ισχύει
είναι μια λέξη για την οποία
ισχύει
![]() , και
, και
![]() .
Από την επαγωγική υπόθεση έπεται ότι
.
Από την επαγωγική υπόθεση έπεται ότι
![]() και συνεπώς
και συνεπώς
![]() .
Ομοίως, αν το πρώτο γράμμα της
.
Ομοίως, αν το πρώτο γράμμα της ![]() είναι
είναι ![]() τότε ο πρώτος κανόνας
παραγωγής από το
τότε ο πρώτος κανόνας
παραγωγής από το ![]() στο
στο ![]() είναι αναγκαστικά ο
είναι αναγκαστικά ο ![]() , άρα
, άρα
![]() , με
, με
![]() και
και
![]() .
Από την επαγωγική υπόθεση
.
Από την επαγωγική υπόθεση
![]() από το οποίο προκύπτει
από το οποίο προκύπτει
![]() .
.
![]()
Αν το πρώτο γράμμα της ![]() είναι
είναι ![]() τότε
τότε ![]() με
με
![]() ,
και
,
και
![]() . Από την επαγωγική υπόθεση προκύπτει ότι
. Από την επαγωγική υπόθεση προκύπτει ότι
![]() , άρα υπάρχει τρόπος να παράγουμε το
, άρα υπάρχει τρόπος να παράγουμε το ![]() από το
μη τερματικό σύμβολο
από το
μη τερματικό σύμβολο ![]() . Αρχίζοντας τότε από το
. Αρχίζοντας τότε από το ![]() , εφαρμόζουμε
τον κανόνα παραγωγής
, εφαρμόζουμε
τον κανόνα παραγωγής ![]() και ακολούθως παράγουμε από το
και ακολούθως παράγουμε από το
![]() το
το ![]() . Συνολικά έχουμε παραγάγει έτσι το
. Συνολικά έχουμε παραγάγει έτσι το ![]() από το
από το ![]() δείχνοντας
σε αυτή την περίπτωση
δείχνοντας
σε αυτή την περίπτωση
![]() .
Ομοίως, αν το πρώτο γράμμα της
.
Ομοίως, αν το πρώτο γράμμα της ![]() είναι το
είναι το ![]() τότε γράφεται
τότε γράφεται
![]() με
με
![]() και
και
![]() , άρα, με την επαγωγική
υπόθεση, ισχύει
, άρα, με την επαγωγική
υπόθεση, ισχύει
![]() . Για να παραγάγουμε λοιπόν τη
. Για να παραγάγουμε λοιπόν τη ![]() από το
από το
![]() ξεκινούμε εφαρμόζοντας τον κανόνα
ξεκινούμε εφαρμόζοντας τον κανόνα ![]() , και ακολούθως παράγουμε
από το
, και ακολούθως παράγουμε
από το ![]() το
το ![]() , παίρνοντας έτσι τελικά το
, παίρνοντας έτσι τελικά το ![]() .
.
Εδώ έχουμε δείξει το επαγωγικό βήμα για την πρώτη ισοδυναμία.
Δείχνουμε τώρα το επαγωγγικό βήμα για
την ισοδυναμία
![]() .
Προσέξτε ότι εδώ υπάρχει ασυμμετρία στην απόδειξη όσον αφορά το ρόλο που
παίζει το
.
Προσέξτε ότι εδώ υπάρχει ασυμμετρία στην απόδειξη όσον αφορά το ρόλο που
παίζει το ![]() και το
και το ![]() ως πρώτο γράμμα της λέξης
ως πρώτο γράμμα της λέξης ![]() .
.
![]()
Έστω ότι το πρώτο γράμμα της λέξης ![]() είναι το
είναι το ![]() .
Τότε αναγκαστικά η πρώτη παραγαγωγή από το
.
Τότε αναγκαστικά η πρώτη παραγαγωγή από το ![]() στο
στο ![]() είναι
η
είναι
η ![]() , οπότε
, οπότε ![]() με
με
![]() και αναγκαστικά τότε
το
και αναγκαστικά τότε
το ![]() πρέπει να είναι παραγόμενο από το
πρέπει να είναι παραγόμενο από το ![]() , άρα
, άρα
![]() και από
την επαγωγική υπόθεση
και από
την επαγωγική υπόθεση
![]() , από το οποίο προκύπτει ότι
, από το οποίο προκύπτει ότι
![]() .
.
Αν το πρώτο γράμμα της ![]() είναι το
είναι το ![]() τότε ο πρώτος κανόνας που εφαρμόζεται
στην παραγωγή της
τότε ο πρώτος κανόνας που εφαρμόζεται
στην παραγωγή της ![]() από το
από το ![]() είναι αναγκαστικά ο
είναι αναγκαστικά ο
![]() ,
οπότε έχουμε
,
οπότε έχουμε
![]() όπου
όπου
![]() ,
και, φυσικά,
,
και, φυσικά,
![]() .
Από την επαγωγική υπόθεση τώρα προκύπτει ότι
.
Από την επαγωγική υπόθεση τώρα προκύπτει ότι
![]() και
και
![]() , από τα οποία προκύπτει
φυσικά ότι
, από τα οποία προκύπτει
φυσικά ότι
![]() .
.
![]()
Αν το πρώτο γράμμα της ![]() είναι το
είναι το ![]() τότε
τότε ![]() με
με
![]() ,
,
![]() , οπότε από την επαγωγική υπόθεση
προκύπτει
, οπότε από την επαγωγική υπόθεση
προκύπτει
![]() . Παράγοντας τώρα από το
. Παράγοντας τώρα από το ![]() με τον κανόνα
παραγωγής
με τον κανόνα
παραγωγής ![]() και συνεχίζοντας παράγοντας από το
και συνεχίζοντας παράγοντας από το ![]() το
το ![]() ,
καταλήγουμε σε μια ακολουθία παραγωγής του
,
καταλήγουμε σε μια ακολουθία παραγωγής του ![]() από το
από το ![]() , δηλ.
, δηλ.
![]() .
.
Αν το πρώτο γράμμα της ![]() είναι το
είναι το ![]() τότε
τότε ![]() με
με
![]() και
και
![]() .
Ισχύει όμως το παρακάτω Λήμμα.
.
Ισχύει όμως το παρακάτω Λήμμα.
Παραλείπουμε την απόδειξη του επαγωγικού βήματος για την τρίτη ισοδυναμία
μια και αυτή είναι εντελώς παρόμοια με τη δεύτερη ισοδυναμία, με τους
ρόλους των ![]() ,
, ![]() και
και ![]() ,
, ![]() εναλλαγμένους.
εναλλαγμένους.
![]()
Το αντίστροφο φυσικά δεν ισχύει όπως δείχνουν πολλά από τα παραδείγματα
που έχουμε δει ως τώρα, π.χ. η γλώσσα
![]() .
.
Απόδειξη.
Έστω ![]() κανονική γλώσσα. Αυτό σημαίνει ότι υπάρχει μια κανονική έκφραση
κανονική γλώσσα. Αυτό σημαίνει ότι υπάρχει μια κανονική έκφραση ![]() για τη γλώσσα. Αρκεί να δείξουμε ότι κάθε κανονική έκφραση περιγράφει
μια context free γλώσσα.
για τη γλώσσα. Αρκεί να δείξουμε ότι κάθε κανονική έκφραση περιγράφει
μια context free γλώσσα.
Αρχίζουμε από τις απλούστερες κανονικές εκφράσεις και το
δείχνουμε σταδιακά για όλες.
Κάνουμε δηλ. επαγωγή ως προς το μήκος της κανονικής έκφρασης.
Αν η κανονική έκφραση ![]() έχει μήκος 1,
τότε είναι αναγκαστικά ένα γράμμα του
έχει μήκος 1,
τότε είναι αναγκαστικά ένα γράμμα του
![]() ,
το σύμβολο
,
το σύμβολο ![]() ή το σύμβολο
ή το σύμβολο ![]() (ανατρέξτε πίσω στον Ορισμό 3).
Αν είναι γράμμα του
(ανατρέξτε πίσω στον Ορισμό 3).
Αν είναι γράμμα του ![]() δηλ.
δηλ.
![]() για κάποιο
για κάποιο
![]() , τότε η γλώσσα
, τότε η γλώσσα ![]() είναι
το μονοσύνολο
είναι
το μονοσύνολο
![]() , το οποίο δίνεται από την CFG
, το οποίο δίνεται από την CFG
![]() .
Αν
.
Αν
![]() τότε
τότε
![]() που δίνεται από την
CFG
που δίνεται από την
CFG
![]() , και αν
, και αν
![]() τότε
τότε
![]() και αυτό το σύνολο δίνεται από τη CFG
και αυτό το σύνολο δίνεται από τη CFG ![]() , που προφανώς
δεν παράγει τίποτα.
, που προφανώς
δεν παράγει τίποτα.
Αν τώρα το μήκος της έκφρασης ![]() είναι μεγαλύτερο του 1 τότε, με βάση τον
ορισμό των κανονικών εκφράσεων, η
είναι μεγαλύτερο του 1 τότε, με βάση τον
ορισμό των κανονικών εκφράσεων, η ![]() είναι της μορφής
είναι της μορφής
Όπως ακριβώς οι κανονικές γλώσσες έχουν αντίστοιχες μηχανές, τα DFA,
ή τα NFA ή τα ![]() -NFA, που αναγνωρίζουν ακριβώς το σύνολο
των κανονικών γλωσσών, έτσι υπάρχει και μια μηχανή, το αυτόματο με στοίβα,
ή Push Down Automaton (PDA) που έχει την ιδότητα ότι μια γλώσσα
-NFA, που αναγνωρίζουν ακριβώς το σύνολο
των κανονικών γλωσσών, έτσι υπάρχει και μια μηχανή, το αυτόματο με στοίβα,
ή Push Down Automaton (PDA) που έχει την ιδότητα ότι μια γλώσσα ![]() είναι context free αν και μόνο αν υπάρχει PDA που την αναγνωρίζει.
Δε θα δείξουμε αυτή την ισοδυναμία εδώ (όπως είχαμε κάνει για τις κανονικές
γλώσσες και τα πεπερασμένα αυτόματα).
είναι context free αν και μόνο αν υπάρχει PDA που την αναγνωρίζει.
Δε θα δείξουμε αυτή την ισοδυναμία εδώ (όπως είχαμε κάνει για τις κανονικές
γλώσσες και τα πεπερασμένα αυτόματα).
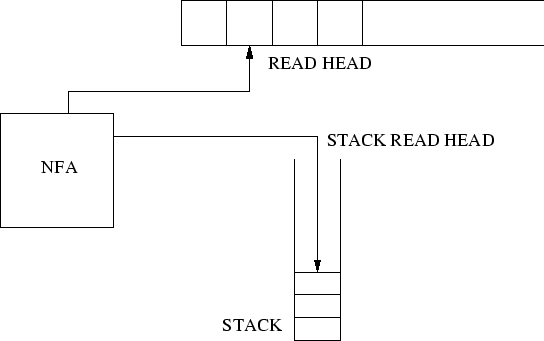
Ένα PDA (Σχήμα 20) αποτελείται από τρία μέρη
Η σύνδεση του NFA με τη στοίβα γίνεται ως εξής: σε κάθε μετάβαση το NFA δεν επιλέγει το σύνολο των δυνατών επομένων καταστάσεων με κριτήριο μόνο το σε ποια κατάσταση βρίσκεται αυτό αλλά κοιτώντας ταυτόχρονα και ποιο είναι το περιεχόμενο της πάνω θέσης μνήμης της στοίβας (η μόνη θέση μνήμης που μπορεί άλλωστε να δει). Επίσης σε κάθε μετάβαση το NFA εκτελεί ενδεχομένως και μια από τις τρεις επιτρεπτές πράξεις στη στοίβα (διαβάζει την κορυφή της, προσθέτει κάτι στην κορυφή της, πετάει την πάνω θέση μνήμης χαμηλώνοντας την κορυφή της στοίβας κατά ένα, ή δεν κάνει τίποτα στη στοίβα).
Το μοντέλο του PDA είναι λειτουργικά ισοδύναμο με προγραμματισμό σε μια συνηθισμένη γλώσσα προγραμματισμού (π.χ. στην C) με τους εξής περιορισμούς και προσθήκες.
| int READ(); | Επιστρέφει τα περιεχόμενα της πάνω θέσης μνήμης της στοίβας ή -1 αν η στοίβα είναι άδεια. |
| POP(); | αδειάζει μια θέση μνήμης από τη στοίβα ή δεν κάνει τίποτα αν η στοίβα είναι ήδη άδεια |
| PUSH(int x); | Γράφει τον αριθμό x στην κορυφή της στοίβας, σε μια νέα θέση μνήμης |
Μη ντετερμινιστικά ``προγράμματα''
Γενικά ο μηχανισμός του μη ντετερμινισμού χρησιμοποιείται σε προβλήματα
αποφάσεων, σε ερωτήματα δηλαδή που φιλοδοξούμε να λύσουμε υπολογιστικά
και τα οποία επιδέχονται ΝΑΙ ή ΟΧΙ απάντηση, όπως ακριβώς είναι
και το πρόβλημα που μας ενδιαφέρει εδώ, να αποφασίζουμε δηλ. αν μια λέξη
που μας δίνεται ανήκει σε μια γλώσσα ![]() ή όχι.
ή όχι.
Η συνάρτηση μέσω της οποίας ``υλοποιείται'' ο μη ντετερμινισμός είναι η
int NF(int x); η οποία επιστρέφει μη ντετερμινιστικά μια
από τις επιλογές
![]() .
Το νόημα της συνάρτησης αυτής είναι
ότι εμείς δεν έχουμε κανένα έλεγχο στο ποια από τις δυνατές επιλογές αυτή
επιλέγει, αλλά πρέπει να γράψουμε το πρόγραμμά μας με τέτοιo τρόπο ώστε
αν αυτή η συνάρτηση επιστρέψει κατά τις κλήσεις της τις κατάλληλες
επιλογές τότε να κάνουμε τη λέξη δεκτή, αν αυτή είναι μέσα στη γλώσσα.
Αλλά, δεν πρέπει να σε καμία
περίπτωση να κάνουμε δεκτή μια λέξη που δεν ανήκει στη γλώσσα
όποιες τιμές κι αν επιστρέψει η NF.
.
Το νόημα της συνάρτησης αυτής είναι
ότι εμείς δεν έχουμε κανένα έλεγχο στο ποια από τις δυνατές επιλογές αυτή
επιλέγει, αλλά πρέπει να γράψουμε το πρόγραμμά μας με τέτοιo τρόπο ώστε
αν αυτή η συνάρτηση επιστρέψει κατά τις κλήσεις της τις κατάλληλες
επιλογές τότε να κάνουμε τη λέξη δεκτή, αν αυτή είναι μέσα στη γλώσσα.
Αλλά, δεν πρέπει να σε καμία
περίπτωση να κάνουμε δεκτή μια λέξη που δεν ανήκει στη γλώσσα
όποιες τιμές κι αν επιστρέψει η NF.
Για να γίνει κατανοητός ο τρόπος χρήσης της NF δείχνουμε παρακάτω μια συνάρτηση σε C η οποία παίρνει δύο ορίσματα number και vector και επιστρέφει 1 αν ο ακέραιος number περιέχεται στον πίνακα vector (ο οποίος έχει 1000 στοιχεία, τα vector[0], ... , vector[999]) και 0 αν δεν περιέχεται.
int NumberInVector(int number, int vector[1000])Πρέπει εδώ να ξεκαθαρίσουμε ότι η συνάρτηση NumberInVector λύνει το πρόβλημα που θέλουμε υπό την εξής έννοια:
{ int location;
location = NF(1000);
if(vector[location]==number) return 1;
return 0;
}
Πρέπει να είναι φανερό με αυτό το παράδειγμα, ότι μη ντετερμινιστικοί αλγόριθμοι δεν μπορούν να υλοποιηθούν. Είναι απλά ένα χρήσιμο θεωρητικό κατασκεύασμα.
Η γλώσσα
![]()
Η γλώσσα
![]() είναι context free
(η γραμματική είναι:
είναι context free
(η γραμματική είναι:
![]() ).
Θα δώσουμε εδώ ένα PDA για τη γλώσσα αυτή.
Ισοδύναμα, θα περιγράψουμε το PDA αυτό σα μια συνάρτηση σε C,
σύμφωνα με αυτά που είπαμε στην προηγούμενη παράγραφο.
Η συνάρτηση αυτή θα μπορεί να χρησιμοποιεί σταθερή σε μέγεθος μνήμη
και θα έχει πρόσβαση στη στοίβα μέσω των συναρτήσεων READ, POP, PUSH
που ορίσαμε στην προηγούμενη παράγραφο.
Τυγχάνει για τη γλώσσα αυτή να μη χρειάζεται ο μη ντετερμινισμός οπότε δε
θα χρησιμοποιήσουμε τη συνάρτηση NF.
).
Θα δώσουμε εδώ ένα PDA για τη γλώσσα αυτή.
Ισοδύναμα, θα περιγράψουμε το PDA αυτό σα μια συνάρτηση σε C,
σύμφωνα με αυτά που είπαμε στην προηγούμενη παράγραφο.
Η συνάρτηση αυτή θα μπορεί να χρησιμοποιεί σταθερή σε μέγεθος μνήμη
και θα έχει πρόσβαση στη στοίβα μέσω των συναρτήσεων READ, POP, PUSH
που ορίσαμε στην προηγούμενη παράγραφο.
Τυγχάνει για τη γλώσσα αυτή να μη χρειάζεται ο μη ντετερμινισμός οπότε δε
θα χρησιμοποιήσουμε τη συνάρτηση NF.
Το πρόγραμμα-PDA φαίνεται παρακάτω. Η συνάρτηση f επιστρέφει
1 αν η λέξη (που τη διαβάζουμε με διαδοχικές κλήσεις στη συνάρτηση INP())
ανήκει στην ![]() και 0 αλλιώς.
Η στρατηγική της συνάρτησης είναι η εξής. Όσο διαβάζουμε μηδενικά τα σπρώχνουμε
πάνω στη στοίβα. Για κάθε άσσο που διαβάζουμε πετάμε κάτι από την στοίβα. Επίσης προσέχουμε
ποτέ να μη διαβάσουμε 0 μετά που έχουμε διαβάσει κάποιο 1.
Αν στο τέλος η στοίβα καταλήξει άδεια δεχόμαστε τη λέξη.
και 0 αλλιώς.
Η στρατηγική της συνάρτησης είναι η εξής. Όσο διαβάζουμε μηδενικά τα σπρώχνουμε
πάνω στη στοίβα. Για κάθε άσσο που διαβάζουμε πετάμε κάτι από την στοίβα. Επίσης προσέχουμε
ποτέ να μη διαβάσουμε 0 μετά που έχουμε διαβάσει κάποιο 1.
Αν στο τέλος η στοίβα καταλήξει άδεια δεχόμαστε τη λέξη.
Ότι ακολουθεί το σύμβολο // αποτελεί σχόλιο και δεν είναι τμήμα του προγράμματος.
int f()
{
int i, SeenOne=0;
a: i = INP();
if(i==0) { //Εδώ διαβάζουμε το επόμενο γράμμα
if(SeenOne) return 0; //0 μετά από 1 απορρίπτεται
PUSH(0); goto a; //Μηδενικά σπρώχνονται στη στοίβα
}
if(i==1) {
SeenOne=1;
if(-1 == READ()) return 0; //Άδειασε η στοίβα πριν την ώρα της
POP(); goto a; //Για κάθε 1 πετάμε ένα 0 από τη στοίβα
}
if(-1 == READ()) return 1; //Αν έχει τελειώσει η λέξη και έχει αδειάσει η στοίβα, δεχόμαστε
}
Παρατηρείστε ότι, πέρα από τη στοίβα, το πρόγραμμα αυτό χργσιμοποιεί πεπερασμένη και προκαθορισμένη μνήμη. Για την ακρίβεια χρησιμοποιεί όλες κι όλες δύο μεταβλητές, τις i (που χρησιμοποιείται για να κρατάει το επόμενο γράμμα ή -1) και SeenOne (που φροντίζουμε να είναι 0 όσο δεν έχουμε ακόμη δει άσσο και μετά να είναι 1). Η μεταβλητή i παίρνει τρεις διαφορετικές τιμές, αρκούν δηλ. 2 λογικά bits για να την αποθηκεύσουμε (μια και με αυτά κωδικοποιούμε 4 διαφορετικές τιμές), ενώ για τη μεταβλητή SeenOne που παίρνει δύο τιμές αρκεί ένα λογικό bit.
Η γλώσσα
![]()
Η γλώσσα
![]() (
(![]() είναι η
λέξη
είναι η
λέξη ![]() γραμμένη ανάποδα) εύκολα φαίνεται ότι είναι
context free. Μια CFG γι' αυτήν είναι απλούστατα η
γραμμένη ανάποδα) εύκολα φαίνεται ότι είναι
context free. Μια CFG γι' αυτήν είναι απλούστατα η
Η σημαντική παρατήρηση εδώ είναι ότι δεν μπορούμε να ξέρουμε πότε έχουμε φτάσει τη μέση της λέξης εισόδου! Αυτή τη βοήθεια αναλαμβάνει να μας δώσει η συνάρτηση NF(), η οποία μας λέει ακριβώς αυτό. Στο παρακάτω πρόγραμμα κάθε κλήση στην NF() κατά τη διάρκεια της εκτέλεσης του προγράμματος ισοδυναμεί με μια ερώτηση (στο Θεό, αν προτιμάτε) για το αν φτάσαμε τη μέση της λέξης ή όχι. Αν ο Θεός μας βοηθήσει με τη σωστή απάντηση θα δεχτούμε τη λέξη, μόνο όμως αν πρέπει να τη δεχτούμε. Δε μπορεί δηλ. να μας κοροϊδέψει με τρόπο ώστε να δεχτούμε μια λέξη ενώ δε θα έπρεπε (επαναλαμβάνουμε ότι είναι πολύ σημαντική αυτή η ασυμμετρία στα μη ντετερμινιστικά προγράμματα).
int g()
{
int i, r, mid=0;
a: i = INP(); //Εδώ διαβάζουμε το επόμενο γράμμα
if(mid == 0) mid = NF(2); //Έχουμε περάσει τη μέση της λέξης;
if(mid == 0) { //Όχι, δε την περάσαμε ακόμη
PUSH(i); goto a;
}
else { //Έχουμε περάσει τη μέση
r = READ(); //Διάβασε την κορυφή της στοίβας
if(r == -1) return 0; //Άδεια στοίβα, απόρριψη
POP();
if(r != i) return 0; //Δεν ταιριάζουν, απόρριψη
goto a; //Ταιριάζουν, συνέχισε
}
if(-1 == READ()) return 1; //Κανένα πρόβλημα και στοίβα άδεια, άρα δεχόμαστε
}
Η γραμμή του παραπάνω προγράμματος όπου χρησιμοποιείται ο μη ντετερμινισμός είναι η if(mid == 0) mid = NF(2);, όπου (αν η μεταβλητή mid δεν έχει ήδη γίνει μια φορά 1, οπότε και μένει για πάντα από κει και πέρα) θέτουμε τη μεταβλητή mid σε 0 ή 1 με μια κλήση στην NF(2). Όταν η NF επιστρέψει 1 θεωρούμε από κει και πέρα ότι έχουμε περάσει τη μέση, και προσπαθούμε με το πρόγραμμα να δούμε αν, με αυτή την υπόθεση μπορούμε να δεχτούμε τη λέξη.
Το πρόγραμμα αυτό χρησιμοποιεί τρεις μεταβλητές κάθε μια από τις οποίες
παίρνει τιμές μέσα στο σύνολο
![]() , οπότε δύο λογικά bits
αρκούν για την αποθήκευση κάθε μιας από αυτές.
, οπότε δύο λογικά bits
αρκούν για την αποθήκευση κάθε μιας από αυτές.
Όπως και στην περίπτωση των κανονικών γλωσσών υπάρχει και για τις context free γλώσσες, ένα ``Λήμμα Άντλησης'' που είναι πολύ χρήσιμο στο να αποδεικνύουμε ότι ορισμένες γλώσσες δεν είναι context free. Η μορφή του είναι πολύ παρόμοια με το Λήμμα Άντλησης για κανονικές γλώσσες κα ο τρόπος χρήσης του επίσης.
Η γλώσσα
![]() δεν είναι context free
δεν είναι context free
Ας υποθέσουμε ότι η ![]() είναι context free. Έστω τότε
είναι context free. Έστω τότε
![]() ο αριθμός που αναφέρεται στο Θεώρημα 11 και
ο αριθμός που αναφέρεται στο Θεώρημα 11 και
![]() . Από το Θεώρημα 11
η λέξη
. Από το Θεώρημα 11
η λέξη ![]() γράφεται ως
γράφεται ως ![]() όπου ισχύουν τα συμπεράσματα
του Θεωρήματος. Παρατηρούμε ότι η λέξη
όπου ισχύουν τα συμπεράσματα
του Θεωρήματος. Παρατηρούμε ότι η λέξη ![]() , που σύμφωνα με το Θεώρημα
έχει μήκος το πολύ
, που σύμφωνα με το Θεώρημα
έχει μήκος το πολύ ![]() , δε μπορεί να περιέχει και
, δε μπορεί να περιέχει και ![]() και
και ![]() , ακριβώς
επειδή το μήκος της δε φτάνει να ``γεφυρώσει'' τα
, ακριβώς
επειδή το μήκος της δε φτάνει να ``γεφυρώσει'' τα ![]() της λέξης
της λέξης ![]() .
Χωρίς βλάβη της γενικότητας υποθέτουμε ότι από τη λέξη αυτή λείπουν τα
.
Χωρίς βλάβη της γενικότητας υποθέτουμε ότι από τη λέξη αυτή λείπουν τα ![]() (και το επιχείρημα είναι εντελώς παρόμοιο αν λείπουν τα
(και το επιχείρημα είναι εντελώς παρόμοιο αν λείπουν τα ![]() ).
Από το Θεώρημα 11 έπεται ότι η λέξη
).
Από το Θεώρημα 11 έπεται ότι η λέξη
![]() (εφαρμόσαμε
το Θεώρημα με
(εφαρμόσαμε
το Θεώρημα με ![]() ).
Αλλά για να πάμε από τη λέξη
).
Αλλά για να πάμε από τη λέξη ![]() στην
στην ![]() σβήσαμε το
σβήσαμε το ![]() και το
και το ![]() , τα οποία
δεν έχουν
, τα οποία
δεν έχουν ![]() μέσα, άρα το πλήθος των
μέσα, άρα το πλήθος των ![]() στη λέξη
στη λέξη ![]() έχει παραμείνει
έχει παραμείνει ![]() .
Το μήκος της
.
Το μήκος της ![]() όμως είναι αυστηρά μικρότερο του
όμως είναι αυστηρά μικρότερο του ![]() (εδώ χρησιμοποιούμε
το (α) από τα συμπεράσματα του Θεωρήματος), άρα δε μπορεί η λέξη
(εδώ χρησιμοποιούμε
το (α) από τα συμπεράσματα του Θεωρήματος), άρα δε μπορεί η λέξη ![]() να ανήκει στην
να ανήκει στην
![]() , όως είχαμε υποθέσει.
Άρα η
, όως είχαμε υποθέσει.
Άρα η ![]() δεν είναι context free.
δεν είναι context free.