Βλέπουμε διάφορα παραδείγματα DFA και των γλωσσών που αναγνωρίζουν.
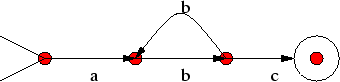
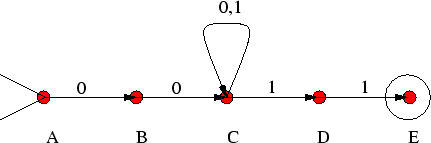
Στο σχήμα 4 που ακολουθεί βλέπουμε ένα αυτόματο
που αναγνωρζει τη γλώσσα
![]() , δηλ. όλες εκείνες
τις λέξεις στο αλφάβητο
, δηλ. όλες εκείνες
τις λέξεις στο αλφάβητο
![]() που αρχίζουν με
που αρχίζουν με ![]() , ακολουθεί
ένας οποιοσδήποτε αριθμός (ακόμη και μηδέν) από αντίγραφα της λέξης
, ακολουθεί
ένας οποιοσδήποτε αριθμός (ακόμη και μηδέν) από αντίγραφα της λέξης ![]() , και
τελειώνουν με τη λέξη
, και
τελειώνουν με τη λέξη ![]() .
.
Συμβολισμός: Στο σχήμα αυτό, όπως και παρακάτω, συμβολίζουμε την αρχική κατάσταση με μια ανοιχτή γωνία (σα ``χωνί'', απ' όπου μπαίνουμε στο αυτόματο) και κάθε τελική κατάσταση μπαίνει μέσα σ'ένα κύκλο.
Παρατήρηση: Προσέξτε ότι στο παραπάνω αυτόματο δεν ισχύει η αρχική μας απαίτηση ότι από κάθε κορυφή πρέπει να φεύγει ακριβώς μια ακμή για κάθε γράμμα του αλφαβήτου (ώστε ό,τι και να διαβάσουμε όταν είμαστε σε κάποια κατάσταση να έχουμε που να πάμε). Για παράδειγμα, για τη δεύτερη κορυφή από αριστερά δεν υπάρχει ακμή με ετικέταπου να ξεκινάει από αυτή. Η σύμβαση που ακολουθούμε είναι ότι αν διαβάσουμε ένα σύμβολο και βρισκόμαστε σε μια κατάσταση από την οποία δεν ξεκινάει ακμή με ετικέτα αυτό το σύμβολο, τότε η λέξη δεν αναγνωρίζεται από το αυτόματο.
Η σύμβαση αυτή ακολουθείται καθαρά για λόγους αισθητικής και κατανόησης του σχεδίου και δεν αλλάζει απολύτως τίποτα στην ουσία. Κάθε αυτόματο που ακολουθεί τη σύμβαση αυτή μπορεί εύκολα να μετετραπεί σε ένα αυτόματο που δε χρησιμοποιεί αυτή τη σύμβαση και έχει πράγματι μια ακμή για κάθε γράμμα από κάθε κορυφή. Απλά δηλώνουμε μια νέα μη τελική κατάσταση, την κατάσταση καταστροφής, όπως επιλέγουμε να την ονομάσουμε, και από κάθε άλλη κατάσταση του αυτομάτου που δεν έχει ακμή από αυτή με ετικέτα έστω
ορίζουμε μια τέτοια ακμή προς την
Ακολουθεί ένα αυτόματο που αναγνωρίζει τη γλώσσα
![]() εκείνων των λέξεων του
εκείνων των λέξεων του
![]() που έχουν μέσα
το πολύ δύο διαδοχικά 1. Ισοδύναμα, είναι εκείνες οι λέξεις στις οποίες
δεν εμφανίζεται η μορφή 111.
που έχουν μέσα
το πολύ δύο διαδοχικά 1. Ισοδύναμα, είναι εκείνες οι λέξεις στις οποίες
δεν εμφανίζεται η μορφή 111.
Στο αυτόματο αυτό όλες οι καταστάσεις είναι τελικές, αλλά αυτό δεν αποτελεί αντίφαση, αφού ακολουθούμε τη σύμβαση της άνω παρατήρησης. Έτσι υπάρχουν πράγματι λέξεις που δεν αναγνωρίζονται από το αυτόματο, μια και κάποιες κορυφές δεν έχουν ακμές που ξεκινάνε από αυτές και για το 0 και το 1. Η μόνη τέτοια κορυφή είναι η δεξιά, και, όντως, η μόνη περίπτωση να απορριφθεί μια λέξη από το αυτόματο είναι να είμαστε στη δεξιά κατάσταση και να διαβάσουμε 1, πράγμα το οποίο συμβαίνει αν και μόνο αν υπάρχουν τρία διαδοχικά 1 στη λέξη.
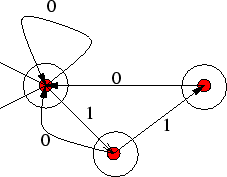
Το επόμενο παράδειγμα είναι κάπως πιο ενδιαφέρον: ![]() είναι η γλώσσα εκείνων
των λέξεων του
είναι η γλώσσα εκείνων
των λέξεων του
![]() που είναι τέτοιες ώστε, μετά το πρώτο 0
υπάρχει τουλάχιστον ένα 0 σε κάθε πεντάδα διαδοχικών γραμμάτων της λέξης.
Για παράδειγμα, οι λέξεις 11111111111, 11111110111101111 είναι στην
που είναι τέτοιες ώστε, μετά το πρώτο 0
υπάρχει τουλάχιστον ένα 0 σε κάθε πεντάδα διαδοχικών γραμμάτων της λέξης.
Για παράδειγμα, οι λέξεις 11111111111, 11111110111101111 είναι στην ![]() ενώ
η λέξη 111111011111 δεν είναι (η τελευταία πεντάδα δεν έχει 0).
Το αυτόματο δίνεται στο παρακάτω σχήμα.
ενώ
η λέξη 111111011111 δεν είναι (η τελευταία πεντάδα δεν έχει 0).
Το αυτόματο δίνεται στο παρακάτω σχήμα.
Πώς πρέπει να σκεφθεί κανείς για να καταλάβει πώς δουλεύει το άνω αυτόματο;
Το κλειδί σε αυτή την περίπτωση, όπως και στις περισσότερες, είναι να αποδώσουμε
κάποιο νόημα στην πρόταση ``βρισκόμαστε στην τάδε κατάσταση''.
Για παράδειγμα, στην κατάσταση ![]() βρισκόμαστε ακριβώς όταν δεν έχουμε διαβάσει
ακόμη το πρώτο 0 της λέξης. Η πρόταση αυτή ισχύει κατ' αρχήν (πριν έχουμε
διαβάσει τίποτε) και διατηρείται
από οποιαδήποτε μετάβαση, αφού φεύγουμε από την κατάσταση
βρισκόμαστε ακριβώς όταν δεν έχουμε διαβάσει
ακόμη το πρώτο 0 της λέξης. Η πρόταση αυτή ισχύει κατ' αρχήν (πριν έχουμε
διαβάσει τίποτε) και διατηρείται
από οποιαδήποτε μετάβαση, αφού φεύγουμε από την κατάσταση ![]() ακριβώς μόλις
διαβάσουμε το πρώτο μηδενικό και δεν ξαναγυρνάμε σε αυτή.
Είναι τώρα φανερό, έχοντας ξεκαθαρίσει τι σημαίνει να βρισκόμαστε στην
κατάσταση
ακριβώς μόλις
διαβάσουμε το πρώτο μηδενικό και δεν ξαναγυρνάμε σε αυτή.
Είναι τώρα φανερό, έχοντας ξεκαθαρίσει τι σημαίνει να βρισκόμαστε στην
κατάσταση ![]() , ότι αυτή πρέπει να είναι τελική κατάσταση, μια και αν ποτέ δε διαβάσουμε
κάποιο 0, ισχύει ο κανόνας που βάλαμε στην αρχή για το ποιες λέξεις ανήκουν
στην
, ότι αυτή πρέπει να είναι τελική κατάσταση, μια και αν ποτέ δε διαβάσουμε
κάποιο 0, ισχύει ο κανόνας που βάλαμε στην αρχή για το ποιες λέξεις ανήκουν
στην ![]() και άρα πρέπει να δεχτούμε τη λέξη.
και άρα πρέπει να δεχτούμε τη λέξη.
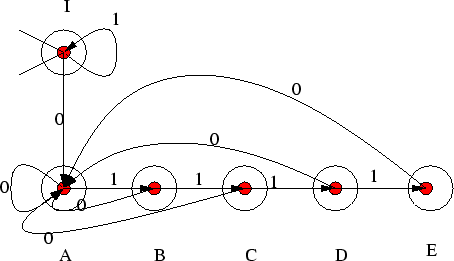
Κάνουμε τώρα την εξής παρατήρηση. Ας πούμε πως ένας άνθρωπος, με λίγη μνήμη, έχει
επιφορτισθεί με το καθήκον να αναγνωρίζει ακριβώς αυτές τις λέξεις.
Αυτός μαθαίνει τα σύμβολα της λέξης ένα-ένα, πρώτα από τα αριστερά, όπως ακριβώς
και το αυτόματο, και πρέπει κάποια στιγμή να πεί αν αυτή η λέξη ανήκει ή όχι
στην ![]() .
Επειδή ακριβώς ο άνθρωπος αυτός έχει λίγη μνήμη, κι επειδή οι λέξεις τις οποίες
κρίνει μπορούν να έχουν οσοδήποτε μεγάλο μήκος, αποφασίζει αντί ανά πάσα στιγμή να θυμάται
ολόκληρη τη λέξη που έχει δει μέχρι τότε, να θυμάται απλώς
πόσο χρόνο πριν είδε το τελευταίο μηδενικό.
Είναι φανερό ότι αυτή η πληροφορία του αρκεί για να αποφασίσει.
Θα απορρίψει δε τη λέξη αν και μόνο αν αυτός ο χρόνος ξεπεράσει το 5 σε κάποια
χρονική στιγμή, γιατί ακριβώς τότε έχει δει μια πεντάδα γεμάτη με 1.
.
Επειδή ακριβώς ο άνθρωπος αυτός έχει λίγη μνήμη, κι επειδή οι λέξεις τις οποίες
κρίνει μπορούν να έχουν οσοδήποτε μεγάλο μήκος, αποφασίζει αντί ανά πάσα στιγμή να θυμάται
ολόκληρη τη λέξη που έχει δει μέχρι τότε, να θυμάται απλώς
πόσο χρόνο πριν είδε το τελευταίο μηδενικό.
Είναι φανερό ότι αυτή η πληροφορία του αρκεί για να αποφασίσει.
Θα απορρίψει δε τη λέξη αν και μόνο αν αυτός ο χρόνος ξεπεράσει το 5 σε κάποια
χρονική στιγμή, γιατί ακριβώς τότε έχει δει μια πεντάδα γεμάτη με 1.
Μετά από αυτή την παρατήρηση το νόημα της κατάστασης ![]() είναι ότι βρίσκεται εκεί
αν έχει δεί 0 ακριβώς πριν από χρόνο 1. Το νόημα της κατάστασης
είναι ότι βρίσκεται εκεί
αν έχει δεί 0 ακριβώς πριν από χρόνο 1. Το νόημα της κατάστασης ![]() ομοίως
είναι ότι έχει δεί το τελευταίο 0 ακριβώς πριν από χρόνο 2, κ.ο.κ., ενώ στην
κατάσταση
ομοίως
είναι ότι έχει δεί το τελευταίο 0 ακριβώς πριν από χρόνο 2, κ.ο.κ., ενώ στην
κατάσταση ![]() βρισκόμαστε αν έχουμε δεί το τελευταίο 0 ακριβώς 5 χρονικές στιγμές πριν.
Είναι φανερό τώρα γιατί η κατάσταση
βρισκόμαστε αν έχουμε δεί το τελευταίο 0 ακριβώς 5 χρονικές στιγμές πριν.
Είναι φανερό τώρα γιατί η κατάσταση ![]() δεν έχει μετάβαση που ξεκινά από αυτή με 1:
αν είδαμε το τελευταίο 0 χρόνο 5 πίσω και μας έρθει 1 πάει να πει πως
έχουμε μόλις συμπληρώσει μια πεντάδα γεμάτη με 1. Άρα δεν υπάρχει λόγος να
συνεχίσουμε γιατί, ό,τι και να δούμε από δω και πέρα, η λέξη πρέπει να απορριφθεί.
δεν έχει μετάβαση που ξεκινά από αυτή με 1:
αν είδαμε το τελευταίο 0 χρόνο 5 πίσω και μας έρθει 1 πάει να πει πως
έχουμε μόλις συμπληρώσει μια πεντάδα γεμάτη με 1. Άρα δεν υπάρχει λόγος να
συνεχίσουμε γιατί, ό,τι και να δούμε από δω και πέρα, η λέξη πρέπει να απορριφθεί.
Έυκολα μπορούμε τώρα να ελέγξουμε ότι οι διάφορες μεταβάσεις στο σχήμα 6
είναι φτιαγμένες ακριβώς ώστε ακολουθώντας αυτές να διατηρείται το νόημα της
κάθε κατάστασης, και άρα το αυτόματο δουλεύει.
Αν, για παράδειγμα, βρισκόμαστε σε μια οποιαδήποτε από τις καταστάσεις
![]() και διαβάσουμε 0 πρέπει να μεταβούμε στην κατάσταση
και διαβάσουμε 0 πρέπει να μεταβούμε στην κατάσταση ![]() αφού μετά τη μετάβασή μας
θα έχουμε διαβάσει 0 ακριβώς χρόνο 1 πριν, και αυτό είναι το νόημα της κατάστασης
αφού μετά τη μετάβασή μας
θα έχουμε διαβάσει 0 ακριβώς χρόνο 1 πριν, και αυτό είναι το νόημα της κατάστασης ![]() .
.
Εισάγουμε τώρα μια παραλλαγή των ντετερμινιστικών αυτομάτων, τα μη ντετερμινιστικά αυτόματα (Non-deterministic Finite Automata ή NFA). Αυτά αποτελούν φαινομενικά μια ενίσχυση του μοντέλου των ντετερμινιστικών αυτομάτων, αφού, από τον ορισμό που θα δώσουμε, κάθε DFA θα είναι και NFA, και άρα οι γλώσσες που αναγνωρίζονται από τα NFA είναι ένα υπερσύνολο των γλωσσών που αναγνωρίζονται από DFA.
Θα δούμε όμως σύντομα ότι αυτό είναι μόνο φαινομενικό, και ότι τα δύο μοντέλα είναι απολύτως ισοδύναμα, όσον αφορά τουλάχιστον το ποιες γλώσσες αναγνωρίζουν. Με άλλα λόγια, θα δούμε μια μέθοδο που για κάθε NFA θα κατασκευάζει ένα ισοδύναμο DFA, ένα DFA δηλ. που θα αναγνωρίζει ακριβώς την ίδια γλώσσα με το δοθέν NFA. Παρ' όλα αυτα το να μελετούμε NFA προσφέρει μερικά πλεονεκτήματα σε σχέση με τα DFA σε ορισμένες περιπτώσεις, όπως θα δούμε στα παραδείγματα.
Ένα μη ντετερμινιστικό αυτόματο είναι λοιπόν ένα DFA αλλά το οποίο για
κάθε κορυφή και για κάθε γράμμα του αλφαβήτου μπορεί να έχει οποιοδήποτε πεπερασμένο
πλήθος από ακμές που ξεκινούν από την κορυφή και έχουν
το γράμμα ως ετικέτα (ακόμη και καμία).
Η σημαντική διαφορά με πριν είναι ότι, όταν διαβάζουμε μια λέξη,
δεν είναι πλέον μονοσήμαντα καθορισμένη η κίνησή μας πάνω στο γράφημα αφού
ενδέχεται να έχουμε περισσότερες από μία επιλογές μετάβασης όντας σε μία κορυφή
και διαβάζοντας ένα γράμμα.
Θεωρούμε ότι μια λέξη ![]() αναγνωρίζεται από ένα NFA αν υπάρχει τρόπος
να κινηθούμε, διαβάζοντας το
αναγνωρίζεται από ένα NFA αν υπάρχει τρόπος
να κινηθούμε, διαβάζοντας το ![]() , πάνω στο γράφημα ώστε να καταλήξουμε σε τελική
κορυφή.
Απορρίπτεται μια λέξη δηλ. αν και μόνο αν κανείς από τους δυνατούς τρόπους
κίνησης δεν καταλήγει σε τελική κορυφή.
, πάνω στο γράφημα ώστε να καταλήξουμε σε τελική
κορυφή.
Απορρίπτεται μια λέξη δηλ. αν και μόνο αν κανείς από τους δυνατούς τρόπους
κίνησης δεν καταλήγει σε τελική κορυφή.
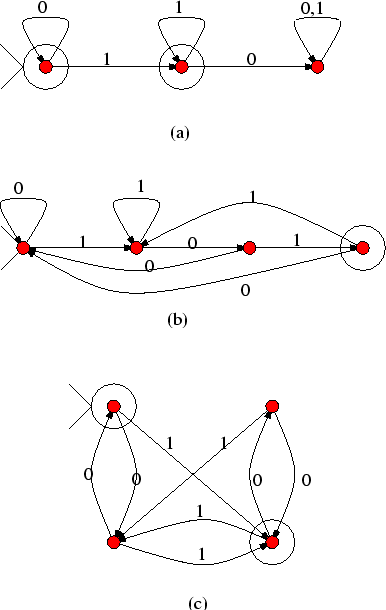
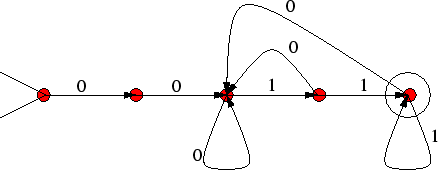
Το ακόλουθο παράδειγμα μη ντετερμινιστικού αυτομάτου αναγνωρίζει τη γλώσσα
![]() .
.
Πρόκειται για NFA και όχι για DFA μια και στη μεσαία κορυφή υπάρχουν δύο ακμές με ετικέτα 1. Παρατηρείστε τη συντομογραφία που επιλέξαμε εδώ: ο βρόγχος (loop) από τη μεσαία κορυφή στον εαυτό της έχει δύο ετικέτες 0 και 1. Αυτό σημαίνει ότι επιτρέπεται να διανύσουμε την κορυφή αυτή όταν διαβάσουμε είτε 0 είτε 1. Θα μπορούσαμε να είχαμε το ίδιο αποτέλεσμα αν φτιαχναμε δύο βρόγχους από την κορυφή αυτή στον εαυτό της, ένα με ετικέτα 0 κι ένα με ετικέτα 1. Επιλέγουμε τη συντομογραφία για καθαρότητα στο σχήμα και τίποτε άλλο.
Γιατί το NFA του σχήματος 8 αναγνωρίζει τη γλώσσα
![]() ;
Παρατηρείστε ότι η
;
Παρατηρείστε ότι η ![]() αποτελείται από εκείνες ακριβώς τις λέξεις που αρχίζουν
με
αποτελείται από εκείνες ακριβώς τις λέξεις που αρχίζουν
με ![]() και τελειώνουν με
και τελειώνουν με ![]() .
Κάθε τέτοια λέξη περνάει από το NFA ως εξής: με τα δύο πρώτα 0 μεταβαίνει
στη μεσαία κορυφή, στην οποία και παραμένει χρησιμοποιώντας το βρόγχο μέχρι
να διαβάσει και το προπροτελευταίο γράμμα. Με τα δύο τελευταία 1 επιλέγει
να κινηθεί προς τα δεξιά για να καταλήξει στη μοναδική τελική κορυφή.
Θα μπορούσε να επιλέξει με τα δύο τελευταία 1 να κινηθεί πάνω στο
βρόγχο της μεσαίας κορυφής, αλλά με αυτό τον τρόπο δεν καταλήγει σε
τελική κορυφή. Αρκεί όμως για την αποδοχή μιας λέξης να υπάρχει έστω και
ένας τρόπος να γίνει αποδεκτή.
.
Κάθε τέτοια λέξη περνάει από το NFA ως εξής: με τα δύο πρώτα 0 μεταβαίνει
στη μεσαία κορυφή, στην οποία και παραμένει χρησιμοποιώντας το βρόγχο μέχρι
να διαβάσει και το προπροτελευταίο γράμμα. Με τα δύο τελευταία 1 επιλέγει
να κινηθεί προς τα δεξιά για να καταλήξει στη μοναδική τελική κορυφή.
Θα μπορούσε να επιλέξει με τα δύο τελευταία 1 να κινηθεί πάνω στο
βρόγχο της μεσαίας κορυφής, αλλά με αυτό τον τρόπο δεν καταλήγει σε
τελική κορυφή. Αρκεί όμως για την αποδοχή μιας λέξης να υπάρχει έστω και
ένας τρόπος να γίνει αποδεκτή.
Αντίστροφα τώρα, αν η λέξη ![]() περνά από το NFA τότε υποχρεωτικά αρχίζει από
δύο 0 (αλλιώς δε μπορεί να πάει δεξιότερα
από τη δεύτερη κορυφή) και τελειώνει σε δύο 1 (αλλιώς δε μπορεί να καταλήξει
στην τελική κορυφή).
περνά από το NFA τότε υποχρεωτικά αρχίζει από
δύο 0 (αλλιώς δε μπορεί να πάει δεξιότερα
από τη δεύτερη κορυφή) και τελειώνει σε δύο 1 (αλλιώς δε μπορεί να καταλήξει
στην τελική κορυφή).
Ας δώσουμε τώρα και ένα DFA για την ίδια γλώσσα:
Είναι μια καλή άσκηση να βεβαιωθείτε (να αποδείξετε) ότι το άνω αυτόματο
αναγνωρίζει τη γλώσσα
![]() . Για να το κάνετε δώστε κάποιο
``νόημα'' στις καταστάσεις, όπως κάναμε παραπάνω για να δείξουμε ότι το
DFA του σχήματος 6 δουλεύει.
. Για να το κάνετε δώστε κάποιο
``νόημα'' στις καταστάσεις, όπως κάναμε παραπάνω για να δείξουμε ότι το
DFA του σχήματος 6 δουλεύει.
Συγκρίνοντας το NFA και το DFA για τη γλώσσα
![]() φαίνεται
καθαρά το πλεονέκτημα του να σχεδιάζουμε NFA αντί για DFA. Επιτρέποντας
στον εαυτό μας ένα πιο διευρυμένο μοντέλο μπορούμε να σχεδιάζουμε ευκολότερα
αυτόματα για συγκεκριμένες γλώσσες, και η απλούστερη κατασκευή συνήθως
επιτρέπει και μια ευκολότερη ανάλυση του γιατί το συγκεκριμένο
αυτόματο δουλεύει. Και, θα δούμε αργότερα, δε χάνεται τίποτα σχεδιάζοντας NFA αντί για
DFA, γιατί αυτά τα δύο υπολογιστικά μοντέλα είναι ισοδύναμα.
Όχι μόνο αυτό, αλλά ο τρόπος μετατροπής ενός NFA σε DFA μπορεί να είναι τελείως
μηχανικός (αλγοριθμικός).
φαίνεται
καθαρά το πλεονέκτημα του να σχεδιάζουμε NFA αντί για DFA. Επιτρέποντας
στον εαυτό μας ένα πιο διευρυμένο μοντέλο μπορούμε να σχεδιάζουμε ευκολότερα
αυτόματα για συγκεκριμένες γλώσσες, και η απλούστερη κατασκευή συνήθως
επιτρέπει και μια ευκολότερη ανάλυση του γιατί το συγκεκριμένο
αυτόματο δουλεύει. Και, θα δούμε αργότερα, δε χάνεται τίποτα σχεδιάζοντας NFA αντί για
DFA, γιατί αυτά τα δύο υπολογιστικά μοντέλα είναι ισοδύναμα.
Όχι μόνο αυτό, αλλά ο τρόπος μετατροπής ενός NFA σε DFA μπορεί να είναι τελείως
μηχανικός (αλγοριθμικός).
Τυπικά τώρα, ένα μη ντετερμινιστικό αυτόματο είναι, όπως και πριν, μια πεντάδα
Στο αυτόματο που φαίνεται στο σχήμα 8
παραπάνω έχουμε
![]() ,
,
![]() ,
, ![]() ,
,
![]() , και
, και